1. Úvod | Posun modelové vrstvy v Crypto AI
Data, modely a výpočet tvoří tři základní pilíře infrastruktury AI - srovnatelné s palivem (data), motorem (model) a energií (výpočet) - všechny nezbytné. Podobně jako evoluce infrastruktury v tradičním AI průmyslu, sektor Crypto AI prošel podobnou trajektorií. Na začátku roku 2024 byl trh ovládán decentralizovanými GPU projekty (jako Akash, Render a io.net), charakterizovanými modelem růstu zaměřeným na velké množství zdrojů soustředěným na surovou výpočetní sílu. Nicméně do roku 2025 se pozornost průmyslu postupně přesunula směrem k modelovým a datovým vrstvám, což znamenalo přechod od konkurence na úrovni nízké infrastruktury k udržitelnějšímu, na aplikace zaměřenému vývoji střední vrstvy.
Obecné LLM vs. Specializované SLM
Tradiční velké jazykové modely (LLMs) silně spoléhají na masivní datasety a komplexní distribuované tréninkové infrastruktury, přičemž velikosti parametrů se často pohybují od 70B do 500B a jednotlivé tréninkové běhy stojí miliony dolarů. Na rozdíl od toho, specializované jazykové modely (SLMs) přijímají lehký režim jemného doladění, který znovu využívá open-source základní modely jako LLaMA, Mistral nebo DeepSeek a kombinuje je s malými, vysoce kvalitními doménově specifickými datasety a nástroji jako LoRA k rychlému budování odborných modelů za výrazně snížené náklady a složitosti.
Je důležité, že SLMs nejsou integrovány zpět do hmotností LLM, ale operují spíše v tandemu s LLM prostřednictvím mechanismů jako je orchestrace založená na agentech, směrování pluginů, hot-swappable LoRA adaptéry a systémy RAG (Retrieval-Augmented Generation). Tato modulární architektura zachovává široké pokrytí LLM, zatímco zvyšuje výkon ve specializovaných doménách – umožňuje vysoce flexibilní, komponovatelný AI systém.
Úloha a limity Crypto AI na úrovni modelu
Crypto AI projekty se z podstaty snaží přímo zlepšit základní schopnosti LLMs. To je způsobeno:
Vysoké technické překážky: Trénování základních modelů vyžaduje masivní datasety, výpočetní výkon a inženýrské odbornosti – schopnosti, které v současnosti mají pouze hlavní technologické hráče v USA (např. OpenAI) a Číně (např. DeepSeek).
Omezení open-source ekosystému: I když jsou modely jako LLaMA a Mixtral open-source, klíčové průlomy stále závisí na institucích výzkumu mimo blockchain a proprietárních inženýrských pipelinech. Projekty na blockchainu mají omezený vliv na úrovni základního modelu.
To však znamená, že Crypto AI stále může vytvářet hodnotu jemným doladěním SLMs na open-source základních modelech a využíváním Web3 prvků, jako je ověřitelnost a pobídky založené na tokenech. Umístěn jako "vrstva rozhraní" AI stacku, projekty Crypto AI obvykle přispívají ve dvou hlavních oblastech:
Důvěryhodná ověřovací vrstva: Záznamy generování modelů, příspěvků dat a záznamy o používání na blockchainu zvyšují sledovatelnost a odolnost vůči manipulacím výstupů AI.
Incentivní mechanismy: Nativní tokeny se používají k odměňování nahrávání dat, volání modelů a provádění agentů – vytváření pozitivní zpětné vazby pro trénink a používání modelů.
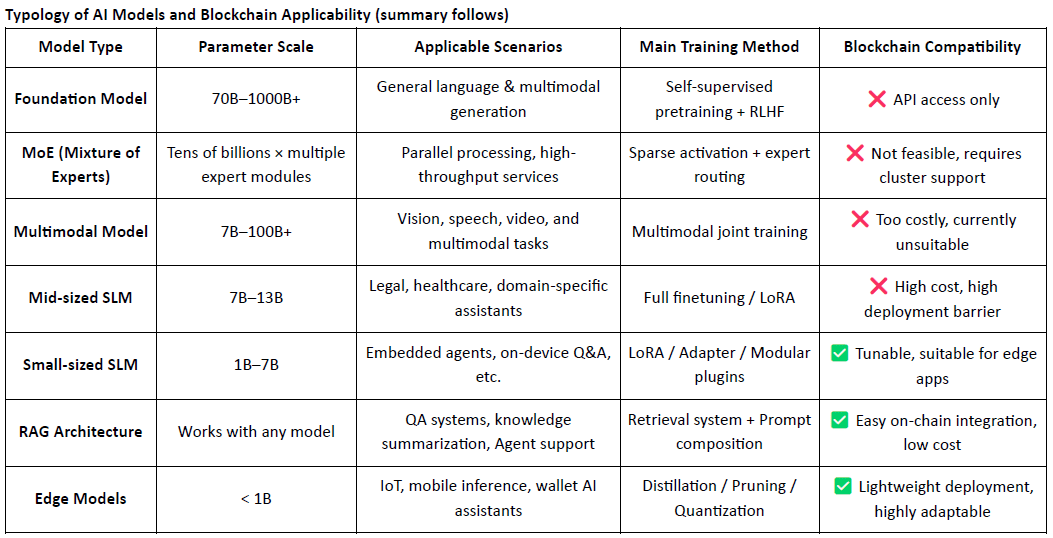
Praktické aplikace projekty Crypto AI zaměřené na modely se primárně koncentrují ve třech oblastech: lehké jemné doladění malých SLMs, integrace a ověřování dat na blockchainu prostřednictvím RAG architektur a místní nasazení a pobízení modelů na okraji. Kombinováním ověřitelnosti blockchainu s mechanismy pobídek založenými na tokenech může Crypto nabídnout jedinečnou hodnotu v těchto scénářích modelů se středními a nízkými zdroji, tvořících diferenciovanou výhodu ve „vrstvě rozhraní“ AI stacku.
Blockchain AI zaměřený na data a modely umožňuje transparentní, neměnné záznamy na blockchainu o každém příspěvku k datům a modelům, což významně zvyšuje důvěryhodnost dat a sledovatelnost trénování modelu. Prostřednictvím mechanismů chytrých kontraktů může automaticky spouštět distribuci odměn, kdykoli jsou data nebo modely využívány, přetvářející činnost AI na měřitelné a obchodovatelné tokenizované hodnoty – čímž vytváří udržitelný systém pobídek. Kromě toho se členové komunity mohou účastnit decentralizované správy hlasováním o výkonu modelu a přispíváním k nastavení pravidel a iteraci pomocí tokenů.
2. Přehled projektu | Vize OpenLedger pro AI Chain
@OpenLedger je jedním z mála blockchainových AI projektů na současném trhu, které se zaměřují konkrétně na mechanismy pobízení dat a modelů. Je průkopníkem konceptu "Platitelná AI", jehož cílem je vybudovat spravedlivé, transparentní a komponovatelné prostředí pro provádění AI, které motivuje přispěvatele dat, vývojáře modelů a tvůrce aplikací AI ke spolupráci na jedné platformě – a vydělávat na blockchainových odměnách na základě skutečných příspěvků.
@OpenLedger nabízí kompletní systém od začátku do konce – od „příspěvku dat“ po „nasazení modelu“ až po „sdílení příjmů na základě použití.“ Jeho hlavní moduly zahrnují:
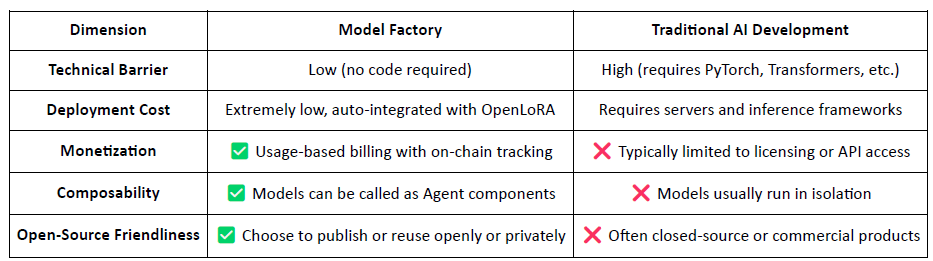
Model Factory: Bez-kódové jemné doladění a nasazení vlastních modelů pomocí open-source LLMs s LoRA;
OpenLoRA: Podporuje koexistenci tisíců modelů, které jsou dynamicky načítány na vyžádání, aby se snížily náklady na nasazení;
PoA (Důkaz přidělení): Sleduje použití na blockchainu, aby spravedlivě rozděloval odměny na základě příspěvků;
Datanets: Strukturální, komunitou řízené datové sítě přizpůsobené vertikálním doménám;
Platforma návrhu modelů: Komponovatelný, volatelný a placený trh modelů na blockchainu.
Společně tyto moduly tvoří daty řízenou a komponovatelnou modelovou infrastrukturu – kladouce základy pro ekonomiku agentů na blockchainu.
Na straně blockchainu, @OpenLedger postavený na OP Stack + EigenDA, poskytuje vysoce výkonné, nízkonákladové a ověřitelné prostředí pro provozování AI modelů a chytrých kontraktů:
Postaveno na OP Stack: Využívá technologický stack Optimism pro vysoký throughput a nízké poplatky;
Vyrovnání na Ethereum Mainnet: Zajišťuje bezpečnost transakcí a integritu aktiv;
EVM-kompatibilní: Umožňuje rychlé nasazení a škálovatelnost pro vývojáře Solidity;
Dostupnost dat napájená EigenDA: Snižuje náklady na úložiště při zajištění ověřitelného přístupu k datům.
Ve srovnání s obecnými AI řetězci jako NEAR – které se zaměřují na základní infrastrukturu, suverenitu dat a rámec „AI Agenti na BOS“ – @OpenLedger je více specializovaný, s cílem vybudovat AI-dedicated chain zaměřený na pobídky na úrovni dat a modelů. Usiluje o to, aby byl vývoj a vyvolání modelu na blockchainu ověřitelné, komponovatelné a udržitelně monetizovatelné. Jako modelově centrální pobídková vrstva v ekosystému Web3, OpenLedger kombinuje hostování modelů ve stylu HuggingFace, fakturaci založenou na použití ve stylu Stripe a skládání na blockchainu podobné Infura, aby podpořil vizi „model-jako-aktivum.“
3. Klíčové komponenty a technická architektura OpenLedger
3.1 Bez-kódová Model Factory
ModelFactory je integrovaná platforma pro jemné doladění velkých jazykových modelů (LLMs) @OpenLedger . Na rozdíl od tradičních rámců jemného doladění nabízí plně grafické, bez-kódové rozhraní, které eliminuje potřebu nástrojů příkazového řádku nebo integrací API. Uživatelé mohou jemně doladit modely pomocí datasetů, které byly povoleny a ověřeny prostřednictvím @OpenLedger , což umožňuje end-to-end pracovní tok pokrývající autorizaci dat, trénink modelu a nasazení.
Klíčové kroky v pracovním postupu zahrnují:
Kontrola přístupu k datům: Uživatelé žádají o přístup k datasetům; po schválení poskytovateli dat jsou dataset automaticky spojeny s tréninkovým rozhraním.
Výběr modelu & konfigurace: Vyberte si z předních LLMs (např. LLaMA, Mistral) a nakonfigurujte hyperparametry prostřednictvím GUI.
Lehké jemné doladění: Vestavěná podpora pro LoRA / QLoRA umožňuje efektivní trénink s reálným sledováním pokroku.
Hodnocení & nasazení: Integrované nástroje umožňují uživatelům hodnotit výkon a exportovat modely pro nasazení nebo opětovné použití v ekosystému.
Interaktivní testovací rozhraní: Chatové uživatelské rozhraní umožňuje uživatelům testovat jemně doladěný model přímo v scénářích Q&A.
RAG přidělení: Výstupy augmentované vyhledáváním zahrnují citace zdrojů pro zvýšení důvěry a auditability.
Architektura ModelFactory se skládá z šesti klíčových modulů, které pokrývají ověřování identity, povolení dat, jemné doladění modelu, hodnocení, nasazení a sledovatelnost založenou na RAG, což poskytuje bezpečnou, interaktivní a monetizovatelnou platformu služeb modelů.
Následuje stručný přehled velkých jazykových modelů aktuálně podporovaných ModelFactory:
LLaMA Série: Jeden z nejvíce přijatých open-source základních modelů, známý svým silným obecným výkonem a živou komunitou.
Mistral: Efektivní architektura s vynikajícím výkonem odvození, ideální pro flexibilní nasazení v prostředích s omezenými zdroji.
Qwen: Vyvinutý společností Alibaba, vyniká v úlohách v čínském jazyce a nabízí silné celkové schopnosti – optimální volba pro vývojáře v Číně.
ChatGLM: Známý pro výjimečný výkon v čínské konverzaci, dobře se hodí pro vertikální zákaznický servis a lokalizované aplikace.
Deepseek: Vyniká v generování kódu a matematickém uvažování, což ho činí ideálním pro inteligentní vývojové asistenty.
Gemma: Lehký model vydaný Googlem, disponující čistou strukturou a snadností použití – vhodný pro rychlé prototypování a experimentování.
Falcon: Dříve měřítkem výkonnosti, nyní spíše vhodný pro základní výzkum nebo srovnávací testování, i když aktivita komunity klesla.
BLOOM: Nabízí silnou vícejazyčnou podporu, ale relativně slabší výkon odvození, což jej činí vhodnějším pro studie pokrytí jazyků.
GPT-2: Klasický raný model, nyní primárně užitečný pro výukové a testovací účely – nasazení v produkci se nedoporučuje.
Zatímco @OpenLedger modelová řada OpenLedger dosud neobsahuje nejnovější vysoce výkonné MoE modely nebo multimodální architektury, tato volba není zastaralá. Spíše odráží strategii „praktičnost první“ založenou na realitě nasazení na blockchainu – zohledňující náklady na odvození, kompatibilitu RAG, integraci LoRA a omezení prostředí EVM.
Model Factory: Bez-kódový nástroj s vestavěným přidělením příspěvků
Jako bez-kódový nástroj Model Factory integruje vestavěný mechanismus Důkazu přidělení napříč všemi modely, aby zajistil práva přispěvatelů dat a vývojářů modelů. Nabízí nízké překážky vstupu, nativní cesty monetizace a skládání, což jej odlišuje od tradičních pracovních toků AI.
Pro vývojáře: Poskytuje kompletní pipeline od vytváření modelu a distribuce po generování příjmů.
Pro platformu: Umožňuje likvidní, komponovatelný ekosystém pro modelová aktiva.
Pro uživatele: Modely a agenti mohou být voláni a skládáni jako API.
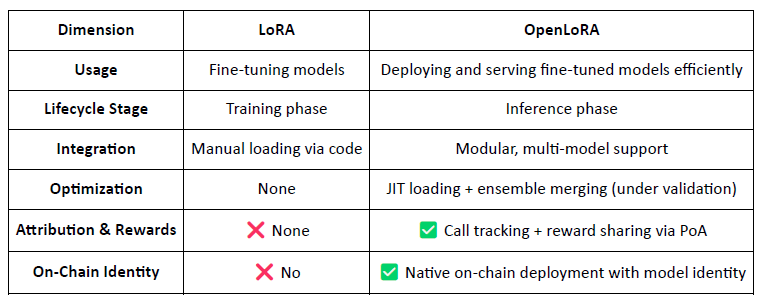
3.2 OpenLoRA, on-chain aktivizace jemně doladěných modelů
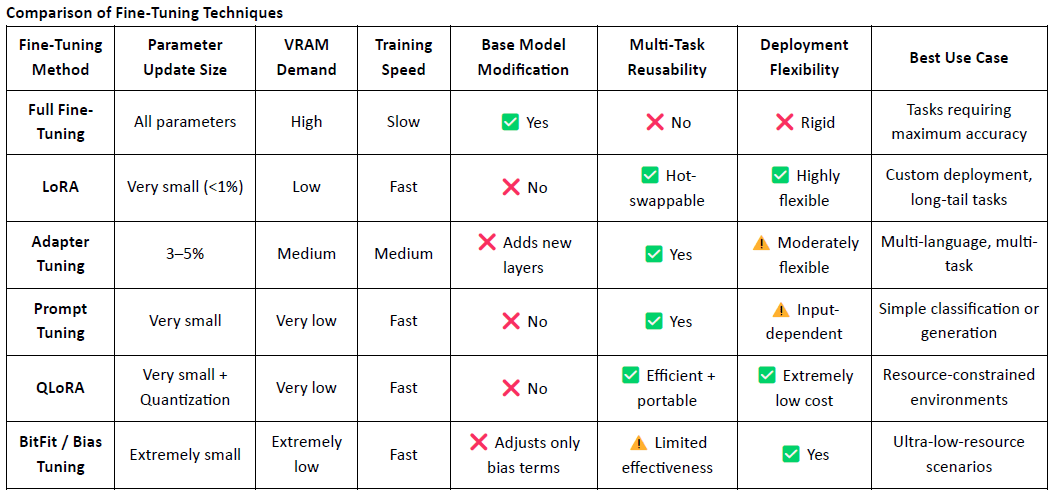
LoRA (Low-Rank Adaptation) je efektivní technika jemného doladění s nízkými nároky na parametry. Funguje tak, že do předem trénovaného velkého modelu vkládá trénovatelné matice s nízkým rangem, aniž by měnila původní hmotnosti modelu, což významně snižuje náklady na trénink a požadavky na úložiště.
Tradiční velké jazykové modely (LLMs), jako jsou LLaMA nebo GPT-3, často obsahují miliardy – nebo dokonce stovky miliard – parametrů. Aby bylo možné tyto modely přizpůsobit specifickým úkolům (např. právní Q&A, lékařské konzultace), je nutné jemné doladění. Klíčová myšlenka LoRA spočívá v zamrznutí původních parametrů modelu a trénování pouze nově přidaných matic, což činí proces vysoce efektivním a snadno nasaditelným.
LoRA se stala hlavním přístupem k jemnému doladění pro nasazení modelů a skládání v oblasti Web3 díky své lehké povaze a flexibilní architektuře.
OpenLoRA je lehký rámec odvození vyvinutý @OpenLedger konkrétně pro vícero nasazení modelů a sdílení zdrojů GPU. Jeho hlavním cílem je vyřešit výzvy vysokých nákladů na nasazení, špatné znovupoužitelnosti modelů a neefektivního využití GPU – což činí vizi „Platitelná AI“ prakticky proveditelnou.
Modulární architektura pro škálovatelné poskytování modelů
OpenLoRA se skládá z několika modulárních komponent, které společně umožňují škálovatelné, nákladově efektivní poskytování modelů:
Úložiště adaptérů LoRA: Jemně doladěné LoRA adaptéry jsou hostovány na @OpenLedger a načítány na vyžádání. To zabraňuje přednačítání všech modelů do paměti GPU a šetří zdroje.
Hostování modelů & vrstva sloučení adaptérů: Všechny adaptéry sdílejí společný základní model. Během odvození jsou adaptéry dynamicky slučovány, podporující vícero adaptérů ve stylu ensemble pro zvýšení výkonu.
Motor odvození: Implementuje optimalizace na úrovni CUDA včetně Flash-Attention, Paged Attention a SGMV k zlepšení efektivity.
Směrovač požadavků & streamování tokenů: Dynamicky směruje požadavky na odvození na odpovídající adaptér a streamuje tokeny pomocí optimalizovaných jader.
End-to-End pracovní postup odvození
Proces odvození následuje zralou a praktickou pipeline:
Inicializace základního modelu: Základní modely jako LLaMA 3 nebo Mistral jsou načteny do paměti GPU.
Dynamické načítání adaptérů: Na požádání jsou specifikované LoRA adaptéry načteny z Hugging Face, Predibase nebo místního úložiště.
Slučování & aktivace: Adaptéry jsou v reálném čase sloučeny do základního modelu, podporující provádění v souboru.
Provádění odvození & streamování tokenů: Sloučený model generuje výstup s streamováním na úrovni tokenů, podporované kvantizací pro rychlost a efektivitu paměti.
Uvolnění zdrojů: Adaptéry jsou po provedení vyloženy, čímž se uvolní paměť a umožní efektivní rotaci tisíců jemně doladěných modelů na jednom GPU.
Klíčové optimalizace
OpenLoRA dosahuje vynikajícího výkonu prostřednictvím:
JIT (Just-In-Time) načítání adaptérů k minimalizaci využití paměti.
Tensor parallelismus a stránková pozornost pro zpracování delších sekvencí a současné provádění.
Slučování více adaptérů pro komponovatelné sloučení modelů.
Flash Attention, předkompilované CUDA jádra a FP8/INT8 kvantizace pro rychlejší, nižší latence odvození.
Tyto optimalizace umožňují vysoce výkonné, nízkonákladové, vícero modelové odvození i v prostředích s jedním GPU – zvláště vhodné pro dlouhé modely, specializované agenty a vysoce personalizovanou AI.
OpenLoRA: Přeměna modelů LoRA na aktiva Web3
Na rozdíl od tradičních LoRA rámců zaměřených na jemné doladění, OpenLoRA transformuje poskytování modelu na nativní Web3, monetizovatelnou vrstvu, což činí každý model:
Identifikovatelné na blockchainu (prostřednictvím ID modelu)
Ekonomicky motivované prostřednictvím použití
Komponovatelné do AI agentů
Odměny distribuovatelné prostřednictvím mechanismu PoA
To umožňuje, aby každý model byl považován za aktivum:
Pohled na výkonnost
Kromě toho @OpenLedger vydal budoucí výkonnostní standardy pro OpenLoRA. Ve srovnání s tradičními nasazeními modelů s plnými parametry je použití GPU paměti výrazně sníženo na 8–12GB, doba přepínání modelu je teoreticky pod 100ms, throughput může dosáhnout přes 2 000 tokenů za sekundu a latence je udržována mezi 20–50ms.
I když jsou tyto čísla technicky dosažitelná, měla by být chápána jako horní odhady výkonnosti spíše než zaručený denní výkon. V reálných výrobních prostředích mohou výsledky kolísat v závislosti na konfiguracích hardwaru, strategiích plánování a složitosti úkolu.
3.3 Datanets: Od vlastnictví dat k inteligenci dat
Vysoce kvalitní, doménově specifická data se stala kritickým aktivem pro budování vysoce výkonných modelů. Datanets slouží jako základní infrastruktura @OpenLedger pro „data jako aktivum“, umožňující shromažďování, ověřování a distribuci strukturovaných datasetů v decentralizovaných sítích. Každý Datanet funguje jako doménově specifický datový sklad, kde přispěvatelé nahrávají data, která jsou ověřena a přidělena na blockchainu. Prostřednictvím transparentních povolení a pobídek umožňují Datanets důvěryhodnou, komunitou řízenou kuraci dat pro trénink a jemné doladění modelů.
Na rozdíl od projektů jako Vana, které se primárně zaměřují na vlastnictví dat, @OpenLedger jde nad rámec shromažďování dat tím, že je přetváří na inteligenci. Prostřednictvím svých třech integrovaných komponent – Datanets (spolupracující, přidělené datasety), Model Factory (nástroje pro jemné doladění bez kódu) a OpenLoRA (sledovatelné, komponovatelné modelové adaptéry) – OpenLedger rozšiřuje hodnotu dat napříč celým cyklem trénování modelu a jeho využití na blockchainu. Zatímco Vana zdůrazňuje „kdo vlastní data“, OpenLedger se zaměřuje na „jak jsou data trénována, vyvolávána a odměňována“, čímž se obě stávají komplementárními pilíři v AI stacku Web3: jeden pro zajištění vlastnictví, druhý pro umožnění monetizace.
3.4 Důkaz přidělení: Redefinice pobídkové vrstvy pro distribuci hodnoty
Důkaz přidělení (PoA) je @OpenLedger OpenLedgerova hlavní mechanismus pro propojení příspěvků s odměnami. Kryptograficky zaznamenává každý příspěvek dat a volání modelu na blockchainu, zajišťující, že přispěvatelé dostávají spravedlivou kompenzaci kdykoli jejich vstupy generují hodnotu. Proces probíhá takto:
Odeslání dat: Uživatelé nahrávají strukturované, doménově specifické datasety a registrují je na blockchainu pro přidělení.
Hodnocení dopadu: Systém hodnotí tréninkovou relevanci každého datasetu na úrovni každého odvození, přičemž zohledňuje kvalitu obsahu a reputaci přispěvatele.
Ověření trénování: Záznamy sledují, které datasety byly skutečně použity v trénování modelu, což umožňuje ověřitelné důkazy o příspěvku.
Distribuce odměn: Přispěvatelé jsou odměňováni v tokenech na základě účinnosti dat a jejich vlivu na výstupy modelu.
Kvalitní správa: Nízkokvalitní, spamové nebo zlovolné data jsou penalizována k udržení integrity trénování.
Ve srovnání s architekturou pobídek Bittensor, která široce pobízí výpočet, data a hodnocení funkcí, @OpenLedger se zaměřuje na realizaci hodnoty na úrovni modelu. PoA není jen mechanismus odměn – je to vícestupňový rámec přidělení pro transparentnost, původ a odměnu napříč celým životním cyklem: od dat po modely po agenty. Přetváří každé vyvolání modelu na sledovanou, odměnitelnou událost, zakotvující ověřitelnou hodnotovou stopu, která sladí pobídky napříč celým AI hodnotovým potrubím.
Odvození augmentované vyhledáváním (RAG) přidělení
RAG (Retrieval-Augmented Generation) je architektura AI, která zlepšuje výstup jazykových modelů tím, že získává externí znalosti – řeší problém halucinovaných nebo zastaralých informací. @OpenLedger představuje RAG přidělení, aby zajistil, že jakýkoli získaný obsah použitý při generování modelu je sledovatelný, ověřitelný a odměňovaný.
RAG pracovní postup přidělení:
Uživatelský dotaz → Získávání dat: AI získává relevantní data z @OpenLedger ’s indexovaných datasetů (Datanets).
Generování odpovědi se sledovaným použitím: Získaný obsah je použit v odpovědi modelu a zaznamenán na blockchainu.
Odměny pro přispěvatele: Přispěvatelé dat jsou odměňováni na základě fondu a relevance získání.
Transparentní citace: Výstupy modelu zahrnují odkazy na původní zdroje dat, čímž zvyšují důvěru a auditability.
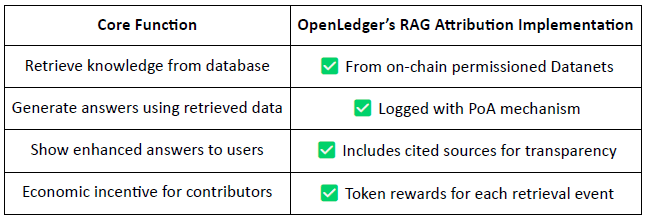
V podstatě, @OpenLedger 's RAG přidělení zajišťuje, že každá odpověď AI je sledovatelná k ověřenému zdroji dat, a přispěvatelé jsou odměňováni na základě frekvence použití, což umožňuje udržitelný cyklus pobídek. Tento systém nejen zvyšuje transparentnost výstupu, ale také vytváří základy pro ověřitelnou, monetizovatelnou a důvěryhodnou infrastrukturu AI.
4. Pokrok projektu a spolupráce v ekosystému
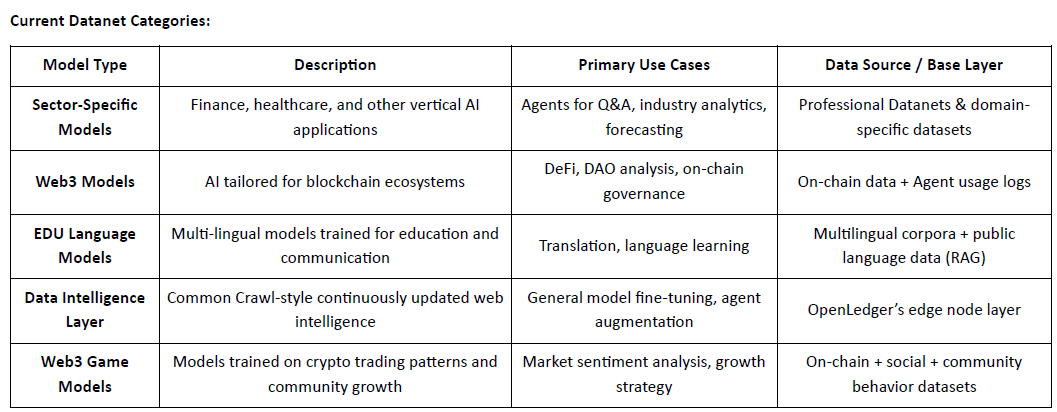
@OpenLedger oficiálně spustil svůj testnet, přičemž první fáze je zaměřena na vrstvu inteligence dat – internetový datový repozitář poháněný komunitou. Tato vrstva agreguje, vylepšuje, klasifikuje a strukturuje surová data do modelově připravené inteligence vhodné pro trénink doménově specifických LLMs na @OpenLedger . Členové komunity mohou provozovat okrajové uzly na svých osobních zařízeních k shromažďování a zpracovávání dat. Na oplátku účastníci získávají body na základě doby provozu a příspěvků k úlohám. Tyto body budou později konvertovatelné na $OPEN tokeny, přičemž konkrétní mechanismus konverze bude oznámen před událostí generování tokenů (TGE).

Epoch 2: Spuštění Datanets
Druhá fáze testnetu zavádí Datanets, systém příspěvků pouze na whitelistu. Účastníci musí projít předběžným hodnocením, aby získali přístup k úlohám jako je validace dat, klasifikace nebo anotace. Odměny jsou založeny na přesnosti, úrovni obtížnosti a hodnocení na žebříčku.
Plán: Směrem k decentralizované ekonomice AI
@OpenLedger si klade za cíl uzavřít smyčku od akvizice dat po nasazení agentů, tvořící plnohodnotný decentralizovaný hodnotový řetězec AI:
Fáze 1: Vrstva inteligence dat
Komunitní uzly shromažďují a zpracovávají reálná internetová data pro strukturované úložiště.Fáze 2: Příspěvky komunity
Komunita přispívá k validaci a zpětné vazbě, tvořícím „Zlatý dataset“ pro trénink modelů.Fáze 3: Vytvoření modelů & nárok
Uživatelé jemně doladí a nárokují vlastnictví specializovaných modelů, což umožňuje monetizaci a skládání.Fáze 4: Vytvoření agentů
Modely mohou být přetvořeny na inteligentní on-chain agenty, nasazené napříč různými scénáři a použitími.
Ecosystem Partners: @OpenLedger collaborates with leading players across compute, infrastructure, tooling, and AI applications:
Výpočet & Hosting: Aethir, Ionet, 0G
Rollup infrastruktura: AltLayer, Etherfi, EigenLayer AVS
Nástroje & Interoperabilita: Ambios, Kernel, Web3Auth, Intract
AI Agenti & Tvůrci modelů: Giza, Gaib, Exabits, FractionAI, Mira, NetMind
Značková dynamika prostřednictvím globálních summitů: V uplynulém roce @OpenLedger uspořádal DeAI summity na hlavních událostech Web3 včetně Token2049 Singapur, Devcon Thajsko, Consensus Hong Kong a ETH Denver. Tyto shromáždění představily špičkové řečníky a projekty v decentralizované AI. Jako jeden z mála týmů na úrovni infrastruktury, kteří neustále organizují vysoce kvalitní průmyslové akce, @OpenLedger významně zvýšil svou viditelnost a hodnotu značky v rámci jak komunity vývojářů, tak širšího ekosystému Crypto AI – položil solidní základ pro budoucí přitažlivost a síťové efekty.
5. Financování a pozadí týmu
@OpenLedger dokončil kolo seed ve výši 11.2 milionu dolarů v červenci 2024, podpořen Polychain Capital, Borderless Capital, Finality Capital, Hashkey, významnými anděly včetně Sreerama Kannana (EigenLayer), Balajiho Srinivasana, Sandeepa (Polygon), Kennyho (Manta), Scotta (Gitcoin), Ajita Tripathiho (Chainyoda), Trevora. Prostředky budou primárně použity na pokrok ve vývoji@OpenLedger 's AI Chain network, včetně mechanismů pobízení modelů, datové infrastruktury a širšího zavedení ekosystému aplikací agentů.
@OpenLedger Openledger bylo založeno Ramem Kumarem, hlavním přispěvatelem k @OpenLedger OpenLedger, který je podnikatelem se sídlem v San Franciscu s pevnými základy jak v AI/ML, tak v blockchainových technologiích. Přináší kombinaci znalostí trhu, technické odbornosti a strategického vedení do projektu. Ram předtím spolupředsedal společnosti R&D zabývající se blockchainem a AI/ML s ročními příjmy přes 35 milionů dolarů a hrál klíčovou roli při rozvoji vysoce dopadových partnerství, včetně strategického společného podniku s dceřinou společností Wal-Martu. Jeho práce se zaměřuje na rozvoj ekosystému a budování aliancí, které podporují reálné přijetí napříč průmysly.
6. Tokenomika a správa
$OPEN je nativní utility token ekosystému @OpenLedger . Podporuje správu platformy, zpracování transakcí, distribuci pobídek a operace AI Agentů – tvořící ekonomický základ pro udržitelnou, on-chain cirkulaci AI modelů a datových aktiv. I když rámec tokenomiky zůstává v raných fázích a podléhá zlepšení, @OpenLedger se blíží svému Token Generation Event (TGE) uprostřed rostoucího zájmu v Asii, Evropě a na Středním východě.
Klíčové užitečné nástroje $OPEN zahrnují:
Správa & rozhodování:
Majitelé OPEN mohou hlasovat o kritických aspektech, jako je financování modelů, správa agentů, upgrady protokolu a přidělení pokladny.Token za plyn & platby poplatků: OPEN slouží jako nativní token za plyn pro @OpenLedger L2, umožňující AI-nativní přizpůsobitelné modely poplatků a snižující závislost na ETH.
Pobídky založené na přidělení:
Vývojáři přispívající kvalitní datasety, modely nebo služby agentů jsou odměňováni v OPEN na základě skutečného použití a dopadu.Meziřetězové mosty:
OPEN podporuje interoperabilitu mezi@OpenLedger L2 a Ethereum L1, což zvyšuje přenosnost a komponovatelnost modelů a agentů.Staking pro AI Agenty:
Provozování AI Agenta vyžaduje staking OPEN. Slabě výkonné nebo zlovolné agenty riskují ztrátu, což motivuje vysokou kvalitu a spolehlivé poskytování služeb.
Na rozdíl od mnoha modelů správy, které spojují vliv výhradně s držením tokenů, @OpenLedger zavádí systém správy založené na zásluhách, kde je hlasovací síla spojena s vytvářením hodnoty. Tento design upřednostňuje přispěvatele, kteří aktivně budují, zdokonalují nebo využívají modely a datasety, spíše než pasivní držitele kapitálu. Tímto způsobem @OpenLedger zajišťuje dlouhodobou udržitelnost a chrání před spekulativní kontrolou – zůstává v souladu se svou vizí transparentní, spravedlivé a komunitou řízené ekonomiky AI.
7. Tržní krajina a konkurenceschopná analýza
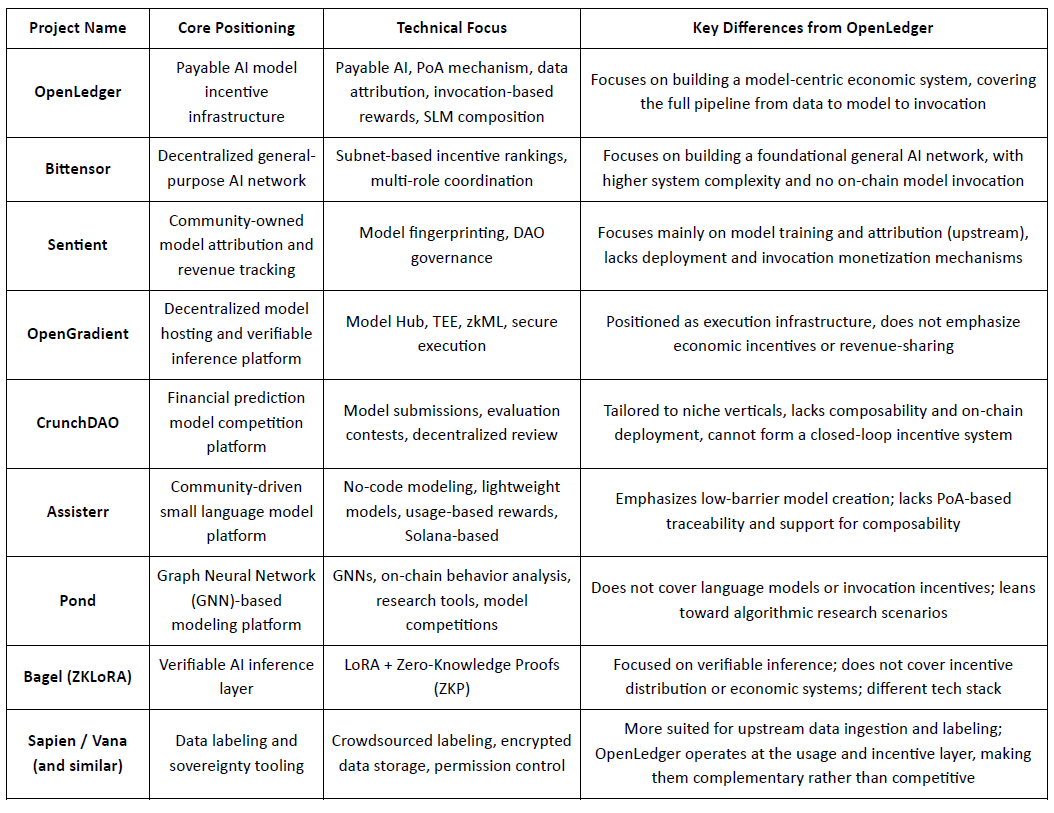
@OpenLedger , umístěný jako infrastruktura pobídek pro modely „Platitelná AI“, si klade za cíl poskytovat ověřitelné, přidělitelnou a udržitelné cesty realizace hodnoty pro přispěvatele dat a vývojáře modelů. Zaměřením na nasazení na blockchainu, pobídky na základě použití a modulární skládání agentů vytvořil odlišnou systémovou architekturu, která vyniká v sektoru Crypto AI. Zatímco žádný existující projekt plně nereplikuje end-to-end rámec @OpenLedger , vykazuje silnou srovnatelnost a potenciální synergie s několika reprezentativními protokoly v oblastech jako jsou pobídkové mechanismy, monetizace modelů a přidělení dat.
Pobídková vrstva: OpenLedger vs. Bittensor
Bittensor je jednou z nejreprezentativnějších decentralizovaných AI sítí, která provozuje vícero rolí spolupracující systém poháněný subnety a hodnocením reputace, přičemž jeho $TAO token podporuje účast modelů, dat a hodnotících uzlů. Na rozdíl od toho @OpenLedger se zaměřuje na sdílení příjmů prostřednictvím nasazení na blockchainu a vyvolání modelů, zdůrazňující lehkou infrastrukturu a koordinaci založenou na agentech. Zatímco oba sdílejí společný základ v logice pobídek, liší se ve složitosti systému a vrstvě ekosystému: Bittensor usiluje o to, aby byl základní vrstvou pro zgeneralizovanou AI schopnost, zatímco @OpenLedger slouží jako vrstva realizace hodnoty na úrovni aplikace.
Vlastnictví modelu & pobídky k vyvolání: OpenLedger vs. Sentient
Sentient představuje koncept „OML (Otevřený, Monetizovatelný, Loajální) AI“, zdůrazňující modely vlastněné komunitou s jedinečnou identitou a sledováním příjmů pomocí Model Fingerprinting. Zatímco oba projekty prosazují uznání přispěvatelů, Sentient se více zaměřuje na fáze tréninku a vytváření modelů, zatímco @OpenLedger se soustředí na nasazení, vyvolání a sdílení příjmů. To činí oba projekty komplementárními v různých fázích hodnotového řetězce AI – Sentient upstream, @OpenLedger downstream.
Hostování modelů & Ověřitelné provádění: OpenLedger vs. OpenGradient
OpenGradient se zaměřuje na budování zabezpečené infrastruktury odvození pomocí TEE a zkML, nabízející decentralizované hostování modelů a důvěryhodné provádění. Zdůrazňuje základní infrastrukturu pro bezpečné AI operace. @OpenLedger na druhé straně, je postaveno kolem cyklu monetizace po nasazení, kombinuje Model Factory, OpenLoRA, PoA a Datanets do kompletního cyklu „trénink–nasazení–vyvolání–výdělek“. Oba fungují v různých vrstvách životního cyklu modelu – OpenGradient na integritě provádění, @OpenLedger na ekonomické pobízení a skládání – s jasným potenciálem pro synergie.
Crowdsourced Modely & Hodnocení: OpenLedger vs. CrunchDAO
CrunchDAO se zaměřuje na decentralizované predikční soutěže ve financích, odměňuje komunity na základě výkonu předloženého modelu. Zatímco se dobře hodí pro vertikální aplikace, postrádá schopnosti pro skládání modelů a nasazení na blockchainu. @OpenLedger nabízí jednotný rámec pro nasazení a komponovatelnou továrnu modelů, s širší aplikovatelností a nativními mechanismy monetizace – činí obě platformy komplementárními ve svých strukturách pobídek.
Komunitou řízené lehké modely: OpenLedger vs. Assisterr
Assisterr, postavený na Solaně, podporuje vytváření malých jazykových modelů (SLMs) prostřednictvím bez-kódových nástrojů a systému odměn založeného na $sASRR. Naopak, @OpenLedger klade větší důraz na sledovatelné přidělení a cykly příjmů napříč vrstvami dat, modelu a vyvolání, využívající svůj mechanismus PoA pro jemně řízené rozdělení pobídek. Assisterr je lépe přizpůsoben pro spolupráci komunity s nízkou překážkou, zatímco @OpenLedger targetuje opakovaně použitelné, komponovatelné modelové infrastruktury.
Model Factory: OpenLedger vs. Pond
Zatímco oba @OpenLedger a Pond nabízejí moduly „Model Factory“, jejich cíloví uživatelé a designové filosofie se výrazně liší. Pond se zaměřuje na modelování založené na grafových neuronových sítích (GNN) k analýze chování na blockchainu, catering pro datové vědce a výzkumníky algoritmů prostřednictvím modelu vývoje řízeného soutěží. Naopak, OpenLedger poskytuje lehké nástroje pro jemné doladění založené na jazykových modelech (např. LLaMA, Mistral), navržené pro vývojáře a technicky nezkušené uživatele s bez-kódovým rozhraním. Zdůrazňuje automatizované tokové pobídky na blockchainu a spolupráci datového-modelového integrace, s cílem vybudovat daty řízenou AI hodnotovou síť.
Ověřitelná cesta odvození: OpenLedger vs. Bagel
Bagel představuje ZKLoRA, rámec pro kryptograficky ověřitelné odvození pomocí LoRA jemně doladěných modelů a nulové znalosti (ZKP) k zajištění správnosti off-chain provádění. Mezitím, @OpenLedger používá LoRA jemné doladění s OpenLoRA k umožnění škálovatelného nasazení a dynamického vyvolání modelu. @OpenLedger také řeší ověřitelné odvození z jiného pohledu - připojením důkazu o přidělení k každému výstupu modelu, vysvětluje, která data přispěla k odvození a jak. To zvyšuje transparentnost, odměňuje nejlepší přispěvatele dat a buduje důvěru v proces rozhodování. Zatímco Bagel se zaměřuje na integritu výpočtu, OpenLedger přináší odpovědnost a vysvětlitelnost prostřednictvím přidělení
Cesta spolupráce dat: OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien a FractionAI se zaměřují na decentralizované označování dat, zatímco Vana a Irys se specializují na vlastnictví dat a suverenitu. @OpenLedger , prostřednictvím svých modulů Datanets + PoA, sleduje používání kvalitních dat a odpovídajícím způsobem distribuuje pobídky na blockchainu. Tyto platformy slouží různým vrstvám hodnotového řetězce dat – označování a správa práv upstream, monetizace a přidělení downstream – což je činí přirozeně spolupracujícími spíše než konkurujícími.
Ve zkratce, OpenLedger zaujímá střední pozici v aktuálním ekosystému Crypto AI jako mostový protokol pro aktivizaci modelů na blockchainu a pobídkové vyvolání. Spojuje upstream tréninkové sítě a datové platformy s downstream vrstvami agentů a aplikacemi koncových uživatelů – stávající se kritickou infrastrukturou, která spojuje nabídku hodnoty modelu s reálným využitím.
8. Závěr | Od dat k modelům – Nechte AI vydělávat také
@OpenLedger si klade za cíl vybudovat infrastrukturu „model-jako-aktivum“ pro svět Web3. Vytvořením kompletního cyklu nasazení na blockchainu, pobídkových mechanismů, přidělení vlastnictví a skládání agentů přináší AI modely do skutečně sledovatelného, monetizovatelného a kolaborativního ekonomického systému poprvé.
Jeho technický stack – skládající se z Model Factory, OpenLoRA, PoA a Datanets – poskytuje:
nástroje pro školení s nízkou překážkou pro vývojáře,
spravedlivé přidělování příjmů pro přispěvatele dat,
komponovatelné vyvolání modelu a mechanismy sdílení odměn pro aplikace.
Toto komplexně aktivuje dlouho opomíjené konce hodnotového řetězce AI: data a modely.
Místo toho, aby byl jen další verzí HuggingFace pro Web3, @OpenLedger se více podobá hybridu HuggingFace + Stripe + Infura, nabízí hostování modelů, fakturaci založenou na použití a programovatelné API na blockchainu. Jak se trendy aktivizace dat, autonomie modelů a modulární koordinace agentů zrychlují, OpenLedger je dobře umístěn, aby se stal centrálním AI řetězcem pod paradigmatem „Platitelná AI“.

