Em plataformas de dados de grande escala, excesso de arquivos pequenos pode tornar-se um problema de confiabilidade operacional, aumentando a sobrecarga de metadados, amplificando leituras, elevando a latência nas etapas finais e causando falhas de execução.
O Small File Doctor é o framework interno da Binance que transforma a limpeza de arquivos pequenos de scripts isolados para um sistema governado, reduzindo os arquivos pequenos de cerca de 59 milhões para 2,9 milhões e economizando cerca de US$ 90 mil a US$ 100 mil por ano em custos de processamento e armazenamento.
O objetivo central do projeto é garantir que a otimização de arquivos seja segura para rodar continuamente em produção, focando esforços apenas onde há melhoria mensurável na latência, estabilidade e custo.
Plataformas modernas operam sobre pipelines de dados. “Produção”, neste contexto, significa os sistemas sempre ativos que coletam, transformam e fornecem dados usados por produtos reais – monitoramento, prevenção de fraudes, analytics, atendimento ao cliente, finanças e diversos outros fluxos de trabalho que precisam ser concluídos pontualmente. Quando esses pipelines desaceleram ou falham, o impacto aparece em dashboards atrasados, metas de serviço perdidas, piora da experiência do usuário ou redução da capacidade de detecção rápida de problemas.
Uma das causas mais comuns de degradação de desempenho oculta em grandes data warehouses são os arquivos pequenos. À medida que os sistemas de dados escalam, gravações frequentes e armazenamento particionado podem gerar dezenas de milhares de arquivos por tabela ou partição, cada um com apenas alguns KB ou MB. O resultado é um sistema que gasta mais tempo abrindo arquivos, lendo metadados e agendando tarefas do que realizando cálculos úteis.
Esta publicação explica como a Binance transformou a otimização de arquivos pequenos em um framework de produção, Small File Doctor, e por que uma “solução de plataforma” frequentemente é a única resposta confiável assim que o número de tabelas e partições ultrapassa o que scripts ad hoc podem gerenciar.
Arquivos pequenos não são inerentemente ruins. Tornam-se um problema quando a quantidade fica tão grande que a plataforma paga sempre um custo fixo: listar arquivos, ler metadados, abrir conexões e agendar tarefas. Em motores de processamento distribuído, esses custos fixos se acumulam, especialmente quando tarefas posteriores escaneiam muitas partições ao mesmo tempo.
Essa combinação – muitas partições e muitos arquivos pequenos em cada uma – aumenta a amplificação de leitura e piora a latência das etapas finais. Latência nas etapas finais importa, pois um pipeline geralmente termina tão rápido quanto sua etapa mais lenta. Uma vez que o tempo do percentil 99 se torna instável, as equipes enfrentam metas de serviço perdidas (SLAs), reexecuções, erros de memória insuficiente e falhas intermitentes difíceis de reproduzir.
O desafio é que limpar arquivos pequenos é fácil de descrever, mas difícil de executar com segurança em larga escala. Reescrever dados em lote afeta armazenamento, processamento e motores de consulta. Sem salvaguardas, uma tarefa bem-intencionada de “unir arquivos” pode se tornar uma nova fonte de incidentes.
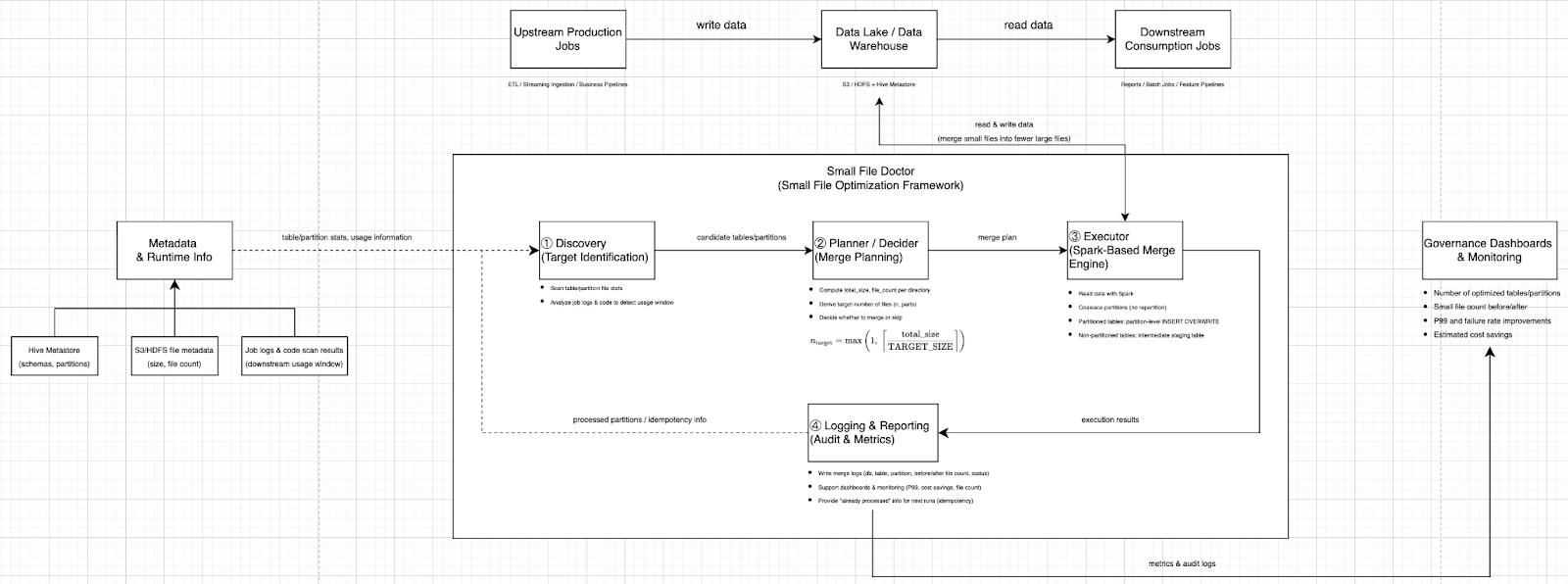
O Small File Doctor é um framework interno que identifica continuamente onde os arquivos pequenos realmente importam, reescreve os dados subjacentes com tamanhos de arquivos mais saudáveis e registra cada ação para que as equipes possam medir o impacto.
Há três metas principais:
Melhorar o desempenho, convergindo os tamanhos dos arquivos para uma meta razoável – no nosso caso, cerca de 256 MB – o que reduz a sobrecarga de metadados e a amplificação de leitura.
Reduzir o esforço operacional, descobrindo automaticamente hotspots e suportando diferentes layouts de tabelas.
Prover governança: toda reescrita é registrada para que a otimização seja associada a resultados mensuráveis como latência, estabilidade e custo.
Em um grande data warehouse, o principal risco é gastar recursos “limpando” tabelas que não afetam resultados de produção. O Small File Doctor começa identificando candidatos usando metadados de armazenamento e sinais de uso, depois foca analisando como os dados são realmente consumidos.
Primeiro, inspeciona metadados de armazenamento de sistemas como S3 e HDFS para calcular contagem e distribuição de tamanho de arquivos entre tabelas e partições. Isso revela hotspots óbvios, como diretórios com número muito alto de arquivos e grande proporção de arquivos minúsculos.
Em seguida, prioriza pelos padrões de acesso. Os casos mais prejudiciais geralmente acontecem quando uma tarefa escaneia uma janela ampla de partições numa só execução e cada partição está cheia de arquivos pequenos. É isso que gera a maior sobrecarga de metadados e pressão de IO. Em contraste, uma tabela onde tarefas posteriores só leem a partição mais recente dificilmente se torna dominante na latência das etapas finais.
Para estimar a janela real de consumo, o sistema analisa rotas de código Spark, Hive e ETL e o comportamento dos jobs para inferir se eles escaneiam um dia, sete dias, trinta dias ou mais em uma execução. Tabelas que agem de forma consistente como “T menos 1 apenas” geralmente são excluídas. Isso é menos sobre pureza e mais sobre ROI: otimizar onde afeta latência e estabilidade, não apenas onde parece organizado.
Por fim, as tabelas e intervalos de partição selecionados são escritos em uma tabela de configuração que funciona como um backlog de otimização, com status que tornam seguro o processamento em lotes controlados.
Em menor escala, as equipes muitas vezes dependem de scripts em loop, passando por tabelas, reescrevendo arquivos e torcendo para que nada quebre. No nível Binance, essa abordagem pode se tornar frágil. Não há registro claro do que foi executado, se ajudou, quais tabelas importam mais ou como evitar que o trabalho interfira nas operações de produção.
O Small File Doctor substitui isso por um fluxo contínuo: pega um backlog claro de otimização, calcula estatísticas de diretório, decide se a união de arquivos vale a pena, executa com segurança e registra os resultados para medição e auditoria.
Para cada diretório alvo – tipicamente uma partição em tabelas particionadas, ou o diretório completo em tabelas não particionadas – o framework estima qual seria o número saudável de arquivos considerando o tamanho alvo e compara com a contagem real e o tamanho médio dos arquivos.
Inclui ainda regras básicas de segurança para evitar trabalho desperdiçado, como ignorar diretórios grandes demais para a janela configurada, evitar união quando há apenas um arquivo e exigir que o tamanho médio esteja materialmente abaixo do alvo antes de acionar a reescrita. Esses controles evitam que o sistema reprocessse repetidamente os mesmos diretórios sem ganhos reais.
O princípio de execução é “unir sem alterar a lógica de negócio, nunca correr o risco de ler e sobrescrever o mesmo caminho de dados ao mesmo tempo”.
O framework lê os dados usando Spark, os reúne para reduzir o número de arquivos de saída sem forçar movimentações globais caras, e escreve os resultados via semântica de tabela SQL ou Hive. Isso importa porque a camada SQL pode impor restrições de segurança na sobrescrita e reduz o risco de conflitos acidentais de leitura e escrita.
Tabelas particionadas são tratadas por diretório de partição. O sistema lê apenas a partição alvo, reúne os resultados, registra uma visão temporária e sobrescreve aquela partição pela semântica SQL, tocando apenas o segmento desejado.
Tabelas não particionadas são mais desafiadoras pois há apenas um diretório. O framework evita padrões inseguros de “ler e sobrescrever o mesmo caminho” usando uma tabela de staging fixa com o mesmo esquema. Os dados são escritos primeiro no staging, depois sobrescritos com segurança na tabela original a partir do staging, mantendo os caminhos de leitura e escrita separados.
Como isso envolve reescrita massiva, salvaguardas de produção são essenciais. O framework limita a concorrência para evitar sobrecarga dos clusters, executa em janelas fora do pico e evita otimizar partições “quentes” que ainda estejam sendo gravadas.
Ele também mantém um log de governança que monitora contagem de arquivos antes e depois, carimbos de tempo e status de execução por tabela e partição. Isso permite comportamento idempotente – uma partição é otimizada no máximo uma vez – e possibilita retomar o trabalho após interrupções sem duplicar esforços.
O Small File Doctor já otimizou 533 tabelas, reduziu arquivos pequenos de cerca de 59 milhões para 2,9 milhões e eliminou falhas de leitura relacionadas a arquivos pequenos nas cargas rastreadas. Segundo modelos de custo, apenas o primeiro nível de tarefas deve economizar entre US$ 90 mil e US$ 100 mil por ano, podendo aumentar conforme o projeto avança.
Hoje, o Small File Doctor roda de forma assíncrona em janelas fora do pico, o que o mantém desacoplado dos pipelines de produção upstream. O ponto negativo é o tempo: tarefas posteriores no mesmo dia podem acessar partições ainda não otimizadas.
A próxima etapa é a integração mais profunda ao scheduler, onde a partição é unida e validada imediatamente após ser produzida e, só então, marcada como pronta para consumo posterior. Isso introduz a saúde dos arquivos como etapa nativa de definição de “finalizado” na produção, trazendo ganhos de performance em tempo mais próximo do real.
Na escala da Binance, arquivos pequenos deixam de ser apenas organização e viram um limite de infraestrutura: aumentam a latência das etapas finais, desestabilizam execuções e desperdiçam processamento. Resolver isso de modo confiável requer um sistema governado, que priorize os dados certos, execute reescritas seguras e vincule o trabalho a resultados mensuráveis.
O Small File Doctor reflete um padrão maior em engenharia de produção: quando o gargalo vira sistêmico, a solução precisa ser sistêmica também. Construir esse tipo de framework interno faz parte de como a Binance mantém pipelines críticos confiáveis à medida que produtos, usuários e atividades escalam simultaneamente.
Inovação na Binance – Otimizando pipelines de funcionalidades em tempo real via união de tarefas
Strategy Factory: O motor de regras com IA da Binance para prevenção de riscos e fraudes
Atenção: Note que pode haver discrepâncias entre este conteúdo original em inglês e quaisquer versões traduzidas (essas versões podem ser geradas por IA). Por favor, consulte a versão original em inglês para obter as informações mais precisas, caso surjam discrepâncias.